Over the past decade, the volume of micro-architecture research leveraging the ChampSim Simulator has grown exponentially. While ChampSim has been instrumental in driving significant innovations within the community, its underlying infrastructure has suffered from a critical bottleneck: the lack of standardized, accessible trace repositories. This scarcity severely impedes the reproducibility of results presented in recent literature.
My own research has not been immune to this challenge; accessing the precise trace sets required to validate prior work has proven increasingly difficult (c.f., [1], [2], [3], [4]). To address this, the TRACK project proposes a FAIR approach to trace management. In the context of scientific research, FAIR is an acronym for the four core principles defined by the GO FAIR Initiative:
Findable: The primary step in (re)using data is its discovery. Metadata and data must be easily discoverable by both humans and machines. Machine-readable metadata are essential for the automatic discovery of datasets, serving as a foundational component of the FAIRification process.
Accessible: Once the required data are located, users must know how to access them, including any necessary authentication or authorization protocols.
Interoperable: Data typically need to be integrated with other datasets. Furthermore, they must be capable of interoperating with diverse applications, workflows, and processing environments.
Reusable: The ultimate goal of FAIR is to optimize data reuse. To achieve this, metadata and data must be richly described with clear provenance and usage licenses, enabling them to be replicated or combined in different experimental settings.
Specifically, the TRACK project is designed to deliver two core components:
A Unified Metadata Standard for Software Traces: We define a common schema for trace metadata compatible with trace-based simulators, including ChampSim and ZSim. This standard ensures the consistent description and organization of trace data across diverse simulation environments.
A Streamlined Command-Line Interface (CLI): We provide a robust and intuitive CLI to simplify user interaction with the trace registry. This tool enables efficient querying, retrieval, and management of traces, lowering the barrier to entry for researchers and facilitating reproducible workflows.
Project Structure
In an effort to address the aforementioned limitations of the current trace-based simulation pipeline, this project provides two main components distributed across two repositories:
The TRACK Schema repository, which defines the standard governing the operation of the trace registry.
A forthcoming repository containing a Command-Line Interface (CLI) designed to simplify interaction with the trace registry.
Contribution
Contributions are welcome. Please refer to the repository guidelines. (Work in Progress)
License
This project is licensed under the Academic Free License (“AFL”) v3.0. See AFL v3.0 on SPDX for details.
Modern server workloads have massive instruction footprints, exacerbating pressure on the processor front-end, and making microarchitectural techniques like L1 instruction (L1I) prefetching essential to alleviate this bottleneck. This paper reveals that although L1I prefetchers deliver significant IPC gains, their full potential remains underutilized due to two main factors: (i) L1I prefetch requests that cross page boundaries require address translation before being issued, and the latency involved in retrieving these translations undermines the timeliness of the L1I prefetches; (ii) the reuse potential of code lines fetched in the cache hierarchy by L1I prefetches is highly variable—while a few lines are accessed multiple times, many are dead-on-arrival. This paper proposes the Instruction Prefetch Centric Cache and TLB Management (IP-CaT), the first microarchitectural scheme orchestrating TLB and cache management to maximize the benefits of L1I prefetching. IP-CaT comprises of two modules: (i) the translation Prefetch Buffer (tPB), a small buffer located alongside the last-level TLB (sTLB) that accommodates page table entries (PTEs) fetched by L1I page-cross prefetches to reduce the address translation cost of L1I prefetching and (ii) the Trimodal Instruction Prefetch Replacement Policy (TIPRP), a decision-tree based replacement policy for the L2 cache (L2C) specialized in the management of lines fetched by L1I prefetches. Our evaluation shows that IP-CaT delivers significant performance benefits when integrated with three state-of-the-art L1I prefetchers (EPI, FNL+MMA, Barça). For example, IP CaT+EPI achieves an 8.7% geomean speedup over EPI across a set of 105 contemporary server workloads. We also show that IP-CaT outperforms the state-of-the-art instruction TLB prefetcher, the leading TLB replacement policy (CHiRP), and the state-of-the-art code-aware, prefetch-aware, and general-purpose cache replacement policies (Emissary, SHiP++, Mockingjay).
@inproceedings{jamet_ip_cat_isca_2026,title={Enhancing Instruction Prefetching via Cache and TLB Management},author={Jamet, Alexandre Valentin and Vavouliotis, Georgios and Torrents, Marti and Chasapis, Dimitrios and Casas, Marc},booktitle={2026 ACM/IEEE 53rd Annual International Symposium on Computer Architecture (ISCA)},year={2026},month=jun,address={Raleigh, North Carolina, United States of America},doi={10.1109/ISCA66397.2026.00159},dimentions={true},note={To appear at ISCA 2026.},}
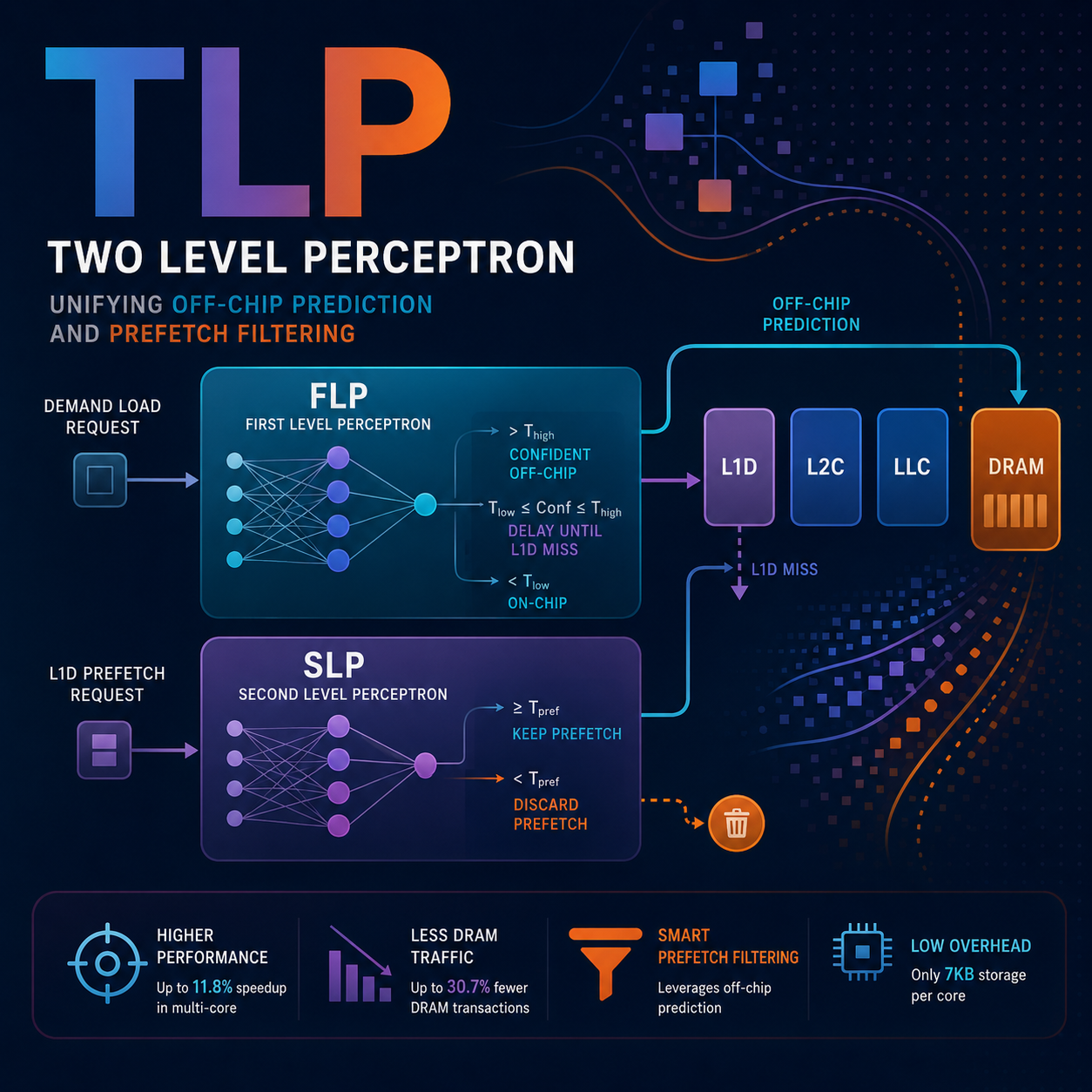
To alleviate the performance and energy overheads of contemporary applications with large data footprints, we propose the Two Level Perceptron (TLP) predictor, a neural mechanism that effectively combines predicting whether an access will be off-chip with adaptive prefetch filtering at the first-level data cache (L1D). TLP is composed of two connected microarchitectural perceptron predictors, named First Level Predictor (FLP) and Second Level Predictor (SLP). FLP performs accurate off-chip prediction by using several program features based on virtual addresses and a novel selective delay component. The novelty of SLP relies on leveraging off-chip prediction to drive L1D prefetch filtering by using physical addresses and the FLP prediction as features. TLP constitutes the first hardware proposal targeting both off-chip prediction and prefetch filtering using a multilevel perceptron hardware approach. TLP only requires 7KB of storage. To demonstrate the benefits of TLP we compare its performance with state-of-the-art approaches using off-chip prediction and prefetch filtering on a wide range of single-core and multi-core workloads. Our experiments show that TLP reduces the average DRAM transactions by 30.7% and 17.7%, as compared to a baseline using state-of-the-art cache prefetchers but no off-chip prediction mechanism, across the single-core and multi-core workloads, respectively, while recent work significantly increases DRAM transactions. As a result, TLP achieves geometric mean performance speedups of 6.2% and 11.8% across single-core and multi-core workloads, respectively. In addition, our evaluation demonstrates that TLP is effective independently of the L1D prefetching logic.
@inproceedings{jamet_tlp_hpca_2024,author={Jamet, Alexandre Valentin and Vavouliotis, Georgios and Jiménez, Daniel A. and Alvarez, Lluc and Casas, Marc},booktitle={2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA)},title={A Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch Filtering},year={2024},volume={},number={},pages={528-542},keywords={Pollution;Microarchitecture;Filtering;Prefetching;Memory management;Random access memory;Bandwidth;Hardware Prefetching;Off-Chip Prediction;Prefetch Filtering;micro-architecture;Graph-Processing},doi={10.1109/HPCA57654.2024.00046},issn={2378-203X},month=mar,note={Patented.},}
Graph-processing workloads have become widespread due to their relevance on a wide range of application domains such as network analysis, path-planning, bioinformatics, and machine learning. Graph-processing workloads have massive data footprints that exceed cache storage capacity and exhibit highly irregular memory access patterns due to data-dependent graph traversals. This irregular behaviour causes graph-processing workloads to exhibit poor data locality, undermining their performance.This paper makes two fundamental observations on the memory access patterns of graph-processing workloads: First, conventional cache hierarchies become mostly useless when dealing with graph-processing workloads, since 78.6% of the accesses that miss in the L1 Data Cache (L1D) result in misses in the L2 Cache (L2C) and in the Last Level Cache (LLC), requiring a DRAM access. Second, it is possible to predict whether a memory access will be served by DRAM or not in the context of graph-processing workloads by observing strides between accesses triggered by instructions with the same Program Counter (PC). Our key insight is that bypassing the L2C and the LLC for highly irregular accesses significantly reduces latency cost while also reducing pressure on the lower levels of the cache hierarchy.Based on these observations, this paper proposes the Large Predictor (LP), a low-cost micro-architectural predictor capable of distinguishing between regular and irregular memory accesses. We propose to serve accesses tagged as regular by LP via the standard memory hierarchy, while irregular access are served via the Side Data Cache (SDC). The SDC is a private per-core set-associative cache placed alongside the L1D specifically aimed at reducing the latency cost of highly irregular accesses while avoiding polluting the rest of the cache hierarchy with data that exhibits poor locality. SDC coupled with LP yields geometric mean speed-ups of 20.3% and 20.2% on single- and multi-core scenarios, respectively, over an architecture featuring a conventional cache hierarchy across a set of contemporary graph-processing workloads. In addition, SDC combined with LP outperforms the Transpose-based Cache Replacement (T-OPT), the state-of-the-art cache replacement policy for graph-processing applications, by 10.9% and 13.8% on single-core and multi-core contexts, respectively. Regarding the hardware budget, SDC coupled with LP requires 10KB of storage per core.
@inproceedings{jamet_sdc_ipdps_2024,author={Jamet, Alexandre Valentin and Vavouliotis, Georgios and Jiménez, Daniel A. and Alvarez, Lluc and Casas, Marc},booktitle={2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS)},title={Practically Tackling Memory Bottlenecks of Graph-Processing Workloads},year={2024},volume={},number={},pages={1034-1045},keywords={Costs;Microarchitecture;Multicore processing;Memory management;Random access memory;Network analyzers;Machine learning;graph processing;cache management;off-chip prediction;micro-architecture},doi={10.1109/IPDPS57955.2024.00096},issn={1530-2075},month=may,}
The vast disparity between Last Level Cache (LLC) and memory latencies has motivated the need for efficient cache management policies. The computer architecture literature abounds with work on LLC replacement policy. Although these works greatly improve over the least-recently-used (LRU) policy, they tend to focus only on the SPEC CPU 2006 benchmark suite - and more recently on the SPEC CPU 2017 benchmark suite - for evaluation. However, these workloads are representative for only a subset of current High-Performance Computing (HPC) workloads. In this paper we evaluate the behavior of a mix of graph processing, scientific and industrial workloads (GAP, XSBench and Qualcomm) along with the well-known SPEC CPU 2006 and SPEC CPU 2017 workloads on state-of-the-art LLC replacement policies such as Multiperspective Reuse Prediction (MPPPB), Glider, Hawkeye, SHiP, DRRIP and SRRIP. Our evaluation reveals that, even though current state-of-the-art LLC replacement policies provide a significant performance improvement over LRU for both SPEC CPU 2006 and SPEC CPU 2017 workloads, those policies are hardly able to capture the access patterns and yield sensible improvement on current HPC and big data workloads due to their highly complex behavior. In addition, this paper introduces two new LLC replacement policies derived from MPPPB. The first proposed replacement policy, Multi-Sampler Multiperspective (MS-MPPPB), uses multiple samplers instead of a single one and dynamically selects the best-behaving sampler to drive reuse distance predictions. The second replacement policy presented in this paper, Multiperspective with Dynamic Features Selector (DS-MPPPB), selects the best behaving features among a set of 64 features to improve the accuracy of the predictions. On a large set of workloads that stress the LLC, MS-MPPPB achieves a geometric mean speed-up of 8.3% over LRU, while DS-MPPPB outperforms LRU by a geometric mean speedup of 8.0%. For big data and HPC workloads, the two proposed techniques present higher performance benefits than state-of-the-art approaches such as MPPPB, Glider and Hawkeye, which yield geometric mean speedups of 7.0%, 5.0% and 4.8% over LRU, respectively.
@inproceedings{jamet_characterization_iiswc_2020,author={Jamet, Alexandre Valentin and Alvarez, Lluc and Jiménez, Daniel A. and Casas, Marc},booktitle={2020 IEEE International Symposium on Workload Characterization (IISWC)},title={Characterizing the impact of last-level cache replacement policies on big-data workloads},year={2020},volume={},number={},pages={134-144},keywords={Benchmark testing;Big Data;Stress;Social networking (online);Roads;Prediction algorithms;Kernel;cache management;big data;graph processing;workload evaluation;micro-architecture},doi={10.1109/IISWC50251.2020.00022},issn={},month=oct,}