Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- ZenodoChampSim Traces for GAP and XSBenchMay 2026Kindly published by Lei Wang as part of his 2026 ISCA paper.
@dataset{jamet_gap_xsbench_champsim_traces_2026, author = {Jamet, Alexandre Valentin and Alvarez, Lluc and Jiménez, Daniel A. and Casas, Marc}, title = {ChampSim Traces for GAP and XSBench}, month = may, year = {2026}, publisher = {Zenodo}, doi = {10.5281/zenodo.20043527}, url = {https://doi.org/10.5281/zenodo.20043527}, dimentions = {true}, note = {Kindly published by Lei Wang as part of his 2026 ISCA paper.} } - Enhancing Instruction Prefetching via Cache and TLB ManagementIn 2026 ACM/IEEE 53rd Annual International Symposium on Computer Architecture (ISCA), Jun 2026To appear at ISCA 2026.
Modern server workloads have massive instruction footprints, exacerbating pressure on the processor front-end, and making microarchitectural techniques like L1 instruction (L1I) prefetching essential to alleviate this bottleneck. This paper reveals that although L1I prefetchers deliver significant IPC gains, their full potential remains underutilized due to two main factors: (i) L1I prefetch requests that cross page boundaries require address translation before being issued, and the latency involved in retrieving these translations undermines the timeliness of the L1I prefetches; (ii) the reuse potential of code lines fetched in the cache hierarchy by L1I prefetches is highly variable—while a few lines are accessed multiple times, many are dead-on-arrival. This paper proposes the Instruction Prefetch Centric Cache and TLB Management (IP-CaT), the first microarchitectural scheme orchestrating TLB and cache management to maximize the benefits of L1I prefetching. IP-CaT comprises of two modules: (i) the translation Prefetch Buffer (tPB), a small buffer located alongside the last-level TLB (sTLB) that accommodates page table entries (PTEs) fetched by L1I page-cross prefetches to reduce the address translation cost of L1I prefetching and (ii) the Trimodal Instruction Prefetch Replacement Policy (TIPRP), a decision-tree based replacement policy for the L2 cache (L2C) specialized in the management of lines fetched by L1I prefetches. Our evaluation shows that IP-CaT delivers significant performance benefits when integrated with three state-of-the-art L1I prefetchers (EPI, FNL+MMA, Barça). For example, IP CaT+EPI achieves an 8.7% geomean speedup over EPI across a set of 105 contemporary server workloads. We also show that IP-CaT outperforms the state-of-the-art instruction TLB prefetcher, the leading TLB replacement policy (CHiRP), and the state-of-the-art code-aware, prefetch-aware, and general-purpose cache replacement policies (Emissary, SHiP++, Mockingjay).
@inproceedings{jamet_ip_cat_isca_2026, title = {Enhancing Instruction Prefetching via Cache and TLB Management}, author = {Jamet, Alexandre Valentin and Vavouliotis, Georgios and Torrents, Marti and Chasapis, Dimitrios and Casas, Marc}, booktitle = {2026 ACM/IEEE 53rd Annual International Symposium on Computer Architecture (ISCA)}, year = {2026}, month = jun, address = {Raleigh, North Carolina, United States of America}, doi = {10.1109/ISCA66397.2026.00159}, dimentions = {true}, note = {To appear at ISCA 2026.}, }

2025
- A Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch FilteringAlexandre Valentin JametIn Proceedings of the 16th International Symposium on Advanced Parallel Processing Technology (APPT 2025), Young Scientist Forum, Jul 2025Invited talk to present the results of the HPCA 2024 paper on the Two Level Perceptron.
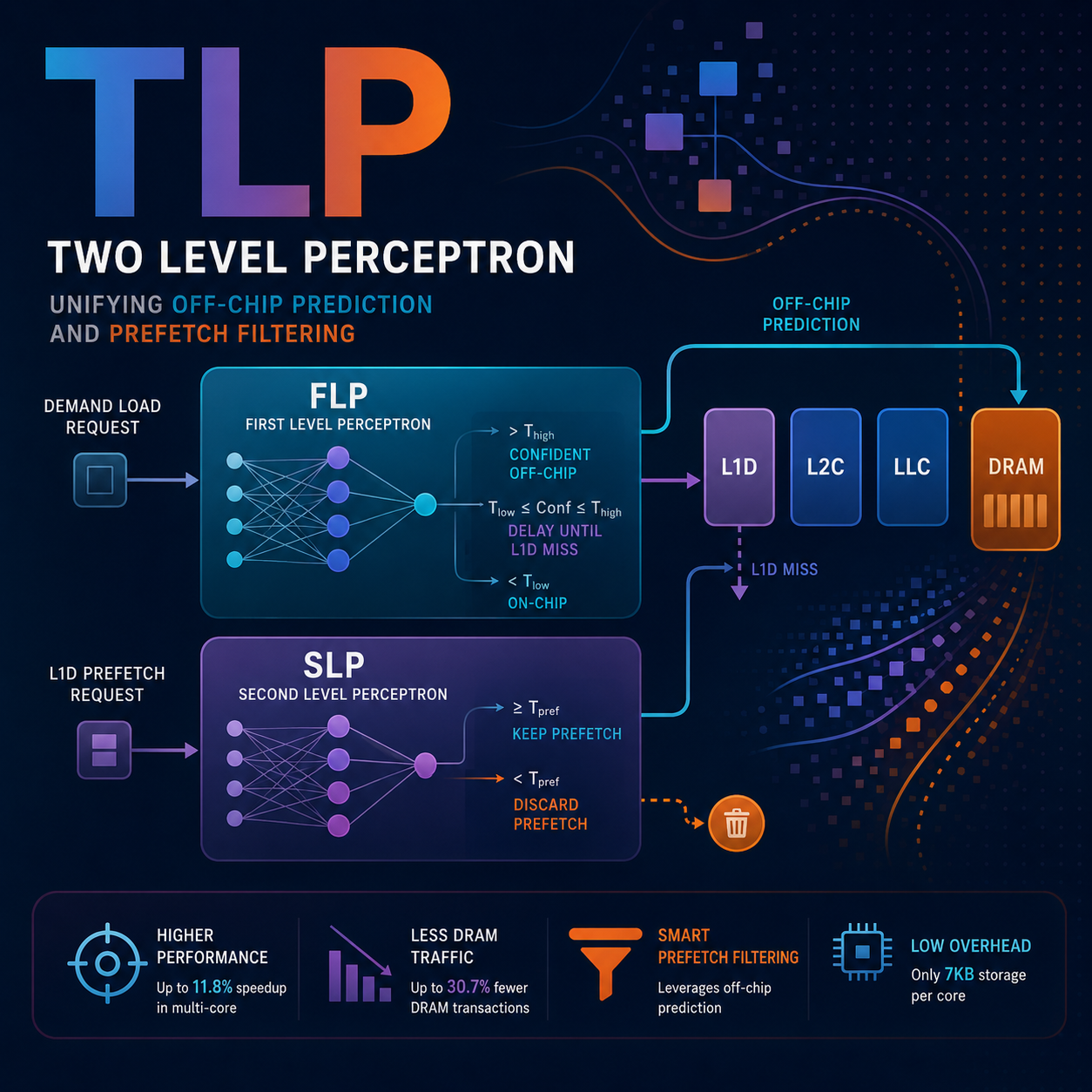
To alleviate the performance and energy overheads of contemporary applications with large data footprints, we propose the Two Level Perceptron (TLP) predictor, a neural mechanism that effectively combines predicting whether an access will be off-chip with adaptive prefetch filtering at the first-level data cache (L1D). TLP is composed of two connected microarchitectural perceptron predictors, named First Level Predictor (FLP) and Second Level Predictor (SLP). FLP performs accurate off-chip prediction by using several program features based on virtual addresses and a novel selective delay component. The novelty of SLP relies on leveraging off-chip prediction to drive L1D prefetch filtering by using physical addresses and the FLP prediction as features. TLP constitutes the first hardware proposal targeting both off-chip prediction and prefetch filtering using a multi-level perceptron hardware approach. TLP only requires 7KB of storage. To demonstrate the benefits of TLP we compare its performance with state-of-the-art approaches using off-chip prediction and prefetch filtering on a wide range of single-core and multicore workloads. Our experiments show that TLP reduces the average DRAM transactions by 30.7% and 17.7%, as compared to a baseline using state-of-the-art cache prefetchers but no offchip prediction mechanism, across the single-core and multi-core workloads, respectively, while recent work significantly increases DRAM transactions. As a result, TLP achieves geometric mean performance speedups of 6.2% and 11.8% across single-core and multi-core workloads, respectively. In addition, our evaluation demonstrates that TLP is effective independently of the L1D prefetching logic.
@inproceedings{jamet_appt_ysf_2025, title = {A Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch Filtering}, author = {Jamet, Alexandre Valentin}, booktitle = {Proceedings of the 16th International Symposium on Advanced Parallel Processing Technology (APPT 2025), Young Scientist Forum}, year = {2025}, month = jul, address = {Athens, Greece}, note = {Invited talk to present the results of the HPCA 2024 paper on the Two Level Perceptron.}, } - Perceptron-based off-chip predictorAlexandre Valentin Jamet, Georgios VAVOULIOTIS, and Marc CASAS, EPO, Jun 2025
The present invention relates to a first-level perceptron (FLP) off-chip predictor communicatively connectable to a computing core and to a DRAM, wherein the core and the DRAM are communicatively connected through a multi-level cache hierarchy of levels L1D, L2C, ..., LLC. The FLP is advantageously adapted with an FLP off-chip prediction mechanism comprising two thresholds, Tlow and Thigh. The invention also relates to a two-level perceptron (TLP) off-chip predictor comprising a first-level perceptron (FLP) off-chip predictor according to any of the preceding claims; and a second-level perceptron (SLP) off-chip predictor communicatively connectable to a multi-level cache hierarchy of levels L1D, L2C, ..., LLC through a L1D prefetcher, wherein the multi-level cache hierarchy is communicatively connected to a computing core and to a DRAM.
@patent{jamet_perceptron-based_2025, title = {Perceptron-based off-chip predictor}, copyright = {All rights reserved}, url = {https://patents.google.com/patent/EP4575807A1/fr?inventor=Alexandre+Valentin+Jamet}, nationality = {EP}, language = {en}, assignee = {Barcelona Supercomputing Center}, type = {European Patent}, location = {EPO}, number = {EP4575807A1}, urldate = {2026-04-08}, author = {Jamet, Alexandre Valentin and VAVOULIOTIS, Georgios and CASAS, Marc}, month = jun, year = {2025}, keywords = {chip, flp, predictor, request, slp}, }
2024
- Interaction between computer architecture and artificial intelligenceAlexandre Valentin JametSep 2024Adivced by Marc Casas Guix and Lluc Alvarez.
Cum Laude
Since its inception with the first computing systems, computer architecture has lived through many revolutions and saw plenty of technological innovations. However, a significant challenge has persisted throughout the evolution of computing systems: the Memory Wall. To address this challenge, architects have devised various latency tolerance techniques, including cache hierarchy, cache replacement policies, hardware prefetching, and off-chip prediction. Cache hierarchy involves the use of intermediate memories, such as caches, to store frequently accessed data close to the processor, thereby reducing memory access latencies. Cache replacement policies determine which data blocks should be stored or evicted from caches based on predictions of future reuse. Hardware prefetching mechanisms aim to bring data blocks that are likely to be needed in the near future into the cache proactively. Off-chip prediction predicts whether a load demand request will benefit from cache access or if it will require a DRAM access, allowing for speculative fetching of data blocks from DRAM to hide memory access latencies. This thesis addresses the challenges of cache management and memory access optimization in modern computer architectures, focusing on improving performance and energy efficiency across a variety of workloads. It presents three main contributions. The first contribution critically assesses the effectiveness of contemporary Last Level Cache (LLC) replacement policies across a diverse spectrum of workloads, encompassing graph processing, scientific, industrial applications, as well as standard benchmark suites like SPEC CPU 2006 and SPEC CPU 2017. Despite exhibiting notable performance enhancements in conventional benchmark scenarios, these existing LLC replacement policies often falter in capturing the nuanced access patterns characteristic of modern High-Performance Computing (HPC) and big data workloads. In response to this challenge, two novel LLC replacement policies, namely Multi-Sampler Multiperspective (MS-MPPPB) and Multiperspective with Dynamic Features Selector (DS-MPPPB), are introduced and rigorously evaluated. Demonstrating superior efficacy across a broad array of workloads, these innovative policies offer heightened performance benefits tailored specifically for HPC and big data applications. The second contribution is dedicated to enhancing memory access patterns, specifically for graph-processing workloads. These workloads are renowned for their irregular memory access patterns and suboptimal data locality. This contribution targets the first level of the cache hierarchy, as careful analysis reveals that, when considering graph-processing workloads, the vast majority of L1D misses eventually require a DRAM access. Introducing the innovative Large Predictor (LP), this endeavor aims to discern between regular and irregular memory accesses, channeling irregular accesses efficiently through a dedicated Side Data Cache (SDC). By synergizing LP with SDC, notable performance enhancements are achieved, surpassing conventional cache hierarchies and state-of-the-art cache replacement policies, particularly within the realm of graph-processing applications. The third contribution presents the Two Level Perceptron (TLP) predictor, a sophisticated approach that integrates off-chip prediction with adaptive prefetch filtering within the first-level data cache (L1D). Leveraging a dual-layered structure composed of the First Level Predictor (FLP) and Second Level Predictor (SLP), TLP effectively mitigates average DRAM transactions while enhancing overall performance across both single-core and multi-core workloads. Collectively, these contributions advance the state-of-the-art in cache management and memory access optimization, providing insights and techniques to enhance the performance and energy efficiency of modern computer architectures across a variety of workloads.
@phdthesis{jamet_2024, type = {Doctoral Thesis}, title = {Interaction between computer architecture and artificial intelligence}, url = {https://hdl.handle.net/2117/452757}, doi = {10.5821/dissertation-2117-452757}, school = {UPC, Departament d'Arquitectura de Computadors}, author = {Jamet, Alexandre Valentin}, year = {2024}, month = sep, note = {Adivced by Marc Casas Guix and Lluc Alvarez.}, } - A Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch FilteringIn 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Mar 2024Patented.
Artifact Evaluation
To alleviate the performance and energy overheads of contemporary applications with large data footprints, we propose the Two Level Perceptron (TLP) predictor, a neural mechanism that effectively combines predicting whether an access will be off-chip with adaptive prefetch filtering at the first-level data cache (L1D). TLP is composed of two connected microarchitectural perceptron predictors, named First Level Predictor (FLP) and Second Level Predictor (SLP). FLP performs accurate off-chip prediction by using several program features based on virtual addresses and a novel selective delay component. The novelty of SLP relies on leveraging off-chip prediction to drive L1D prefetch filtering by using physical addresses and the FLP prediction as features. TLP constitutes the first hardware proposal targeting both off-chip prediction and prefetch filtering using a multilevel perceptron hardware approach. TLP only requires 7KB of storage. To demonstrate the benefits of TLP we compare its performance with state-of-the-art approaches using off-chip prediction and prefetch filtering on a wide range of single-core and multi-core workloads. Our experiments show that TLP reduces the average DRAM transactions by 30.7% and 17.7%, as compared to a baseline using state-of-the-art cache prefetchers but no off-chip prediction mechanism, across the single-core and multi-core workloads, respectively, while recent work significantly increases DRAM transactions. As a result, TLP achieves geometric mean performance speedups of 6.2% and 11.8% across single-core and multi-core workloads, respectively. In addition, our evaluation demonstrates that TLP is effective independently of the L1D prefetching logic.
@inproceedings{jamet_tlp_hpca_2024, author = {Jamet, Alexandre Valentin and Vavouliotis, Georgios and Jiménez, Daniel A. and Alvarez, Lluc and Casas, Marc}, booktitle = {2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA)}, title = {A Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch Filtering}, year = {2024}, volume = {}, number = {}, pages = {528-542}, keywords = {Pollution;Microarchitecture;Filtering;Prefetching;Memory management;Random access memory;Bandwidth;Hardware Prefetching;Off-Chip Prediction;Prefetch Filtering;micro-architecture;Graph-Processing}, doi = {10.1109/HPCA57654.2024.00046}, issn = {2378-203X}, month = mar, note = {Patented.}, } - Practically Tackling Memory Bottlenecks of Graph-Processing WorkloadsIn 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS), May 2024
Graph-processing workloads have become widespread due to their relevance on a wide range of application domains such as network analysis, path-planning, bioinformatics, and machine learning. Graph-processing workloads have massive data footprints that exceed cache storage capacity and exhibit highly irregular memory access patterns due to data-dependent graph traversals. This irregular behaviour causes graph-processing workloads to exhibit poor data locality, undermining their performance.This paper makes two fundamental observations on the memory access patterns of graph-processing workloads: First, conventional cache hierarchies become mostly useless when dealing with graph-processing workloads, since 78.6% of the accesses that miss in the L1 Data Cache (L1D) result in misses in the L2 Cache (L2C) and in the Last Level Cache (LLC), requiring a DRAM access. Second, it is possible to predict whether a memory access will be served by DRAM or not in the context of graph-processing workloads by observing strides between accesses triggered by instructions with the same Program Counter (PC). Our key insight is that bypassing the L2C and the LLC for highly irregular accesses significantly reduces latency cost while also reducing pressure on the lower levels of the cache hierarchy.Based on these observations, this paper proposes the Large Predictor (LP), a low-cost micro-architectural predictor capable of distinguishing between regular and irregular memory accesses. We propose to serve accesses tagged as regular by LP via the standard memory hierarchy, while irregular access are served via the Side Data Cache (SDC). The SDC is a private per-core set-associative cache placed alongside the L1D specifically aimed at reducing the latency cost of highly irregular accesses while avoiding polluting the rest of the cache hierarchy with data that exhibits poor locality. SDC coupled with LP yields geometric mean speed-ups of 20.3% and 20.2% on single- and multi-core scenarios, respectively, over an architecture featuring a conventional cache hierarchy across a set of contemporary graph-processing workloads. In addition, SDC combined with LP outperforms the Transpose-based Cache Replacement (T-OPT), the state-of-the-art cache replacement policy for graph-processing applications, by 10.9% and 13.8% on single-core and multi-core contexts, respectively. Regarding the hardware budget, SDC coupled with LP requires 10KB of storage per core.
@inproceedings{jamet_sdc_ipdps_2024, author = {Jamet, Alexandre Valentin and Vavouliotis, Georgios and Jiménez, Daniel A. and Alvarez, Lluc and Casas, Marc}, booktitle = {2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS)}, title = {Practically Tackling Memory Bottlenecks of Graph-Processing Workloads}, year = {2024}, volume = {}, number = {}, pages = {1034-1045}, keywords = {Costs;Microarchitecture;Multicore processing;Memory management;Random access memory;Network analyzers;Machine learning;graph processing;cache management;off-chip prediction;micro-architecture}, doi = {10.1109/IPDPS57955.2024.00096}, issn = {1530-2075}, month = may, }
2023
- ZenodoA Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch FilteringAlexandre Valentin JametNov 2023Traces - Volume 3
@dataset{jamet_2023_10088525, author = {Jamet, Alexandre Valentin}, title = {A Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch Filtering }, note = {Traces - Volume 3}, month = nov, year = {2023}, publisher = {Zenodo}, version = {1.0.0}, doi = {10.5281/zenodo.10088525}, url = {https://doi.org/10.5281/zenodo.10088525}, } - ZenodoA Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch FilteringAlexandre Valentin JametNov 2023Traces - Volume 2
@dataset{jamet_2023_10088347, author = {Jamet, Alexandre Valentin}, title = {A Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch Filtering }, note = {Traces - Volume 2}, month = nov, year = {2023}, publisher = {Zenodo}, version = {1.0.0}, doi = {10.5281/zenodo.10088347}, url = {https://doi.org/10.5281/zenodo.10088347}, } - ZenodoA Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch FilteringAlexandre Valentin JametNov 2023Traces - Volume 1
@dataset{jamet_2023_10083542, author = {Jamet, Alexandre Valentin}, title = {A Two Level Neural Approach Combining Off-Chip Prediction with Adaptive Prefetch Filtering }, note = {Traces - Volume 1}, month = nov, year = {2023}, publisher = {Zenodo}, version = {1.0.0}, doi = {10.5281/zenodo.10083542}, url = {https://doi.org/10.5281/zenodo.10083542}, } - Characterizing the impact of graph-processing workloads on modern CPU’s cache hierarchyAlexandre Valentin Jamet, Lluc Alvarez, and Marc CasasIn 10th BSC Doctoral Symposium, May 2023
In recent years, graph-processing has become an essential class of workloads with applications in a rapidly growing number of fields. Graph-processing typically uses large input sets, often in multi-gigabyte scale, and data-dependent graph traversal methods exhibiting irregular memory access patterns. Recent work [1] demonstrate that, due to the highly irregular memory access patterns of data-dependent graph traversals, state-of-the-art graph-processing workloads spend up to 80% of the total execution time waiting for memory accesses to be served by the DRAM. The vast disparity between the Last Level Cache (LLC) and main memory latencies is a problem that has been addressed for years in computer architecture. One of the prevailing approaches when it comes to mitigating this performance gap between modern CPUs and DRAM is cache replacement policies. In this work, we characterize the challenges drawn by graph-processing workloads and evaluate the most relevant cache replacement policies.
@inproceedings{valentin_jamet_alvarez_casas_2023, address = {Barcelona, Spain}, booktitle = {10th BSC Doctoral Symposium}, title = {Characterizing the impact of graph-processing workloads on modern CPU's cache hierarchy}, url = {https://hdl.handle.net/2117/427760}, publisher = {Barcelona Supercomputing Center}, author = {Jamet, Alexandre Valentin and Alvarez, Lluc and Casas, Marc}, year = {2023}, month = may, keywords = {cache management; cache bypassing; big data; graph processing; workload evaluation; irregular workloads; microarchitecture}, }
2020
- Characterizing the impact of last-level cache replacement policies on big-data workloadsIn 2020 IEEE International Symposium on Workload Characterization (IISWC), Oct 2020
The vast disparity between Last Level Cache (LLC) and memory latencies has motivated the need for efficient cache management policies. The computer architecture literature abounds with work on LLC replacement policy. Although these works greatly improve over the least-recently-used (LRU) policy, they tend to focus only on the SPEC CPU 2006 benchmark suite - and more recently on the SPEC CPU 2017 benchmark suite - for evaluation. However, these workloads are representative for only a subset of current High-Performance Computing (HPC) workloads. In this paper we evaluate the behavior of a mix of graph processing, scientific and industrial workloads (GAP, XSBench and Qualcomm) along with the well-known SPEC CPU 2006 and SPEC CPU 2017 workloads on state-of-the-art LLC replacement policies such as Multiperspective Reuse Prediction (MPPPB), Glider, Hawkeye, SHiP, DRRIP and SRRIP. Our evaluation reveals that, even though current state-of-the-art LLC replacement policies provide a significant performance improvement over LRU for both SPEC CPU 2006 and SPEC CPU 2017 workloads, those policies are hardly able to capture the access patterns and yield sensible improvement on current HPC and big data workloads due to their highly complex behavior. In addition, this paper introduces two new LLC replacement policies derived from MPPPB. The first proposed replacement policy, Multi-Sampler Multiperspective (MS-MPPPB), uses multiple samplers instead of a single one and dynamically selects the best-behaving sampler to drive reuse distance predictions. The second replacement policy presented in this paper, Multiperspective with Dynamic Features Selector (DS-MPPPB), selects the best behaving features among a set of 64 features to improve the accuracy of the predictions. On a large set of workloads that stress the LLC, MS-MPPPB achieves a geometric mean speed-up of 8.3% over LRU, while DS-MPPPB outperforms LRU by a geometric mean speedup of 8.0%. For big data and HPC workloads, the two proposed techniques present higher performance benefits than state-of-the-art approaches such as MPPPB, Glider and Hawkeye, which yield geometric mean speedups of 7.0%, 5.0% and 4.8% over LRU, respectively.
@inproceedings{jamet_characterization_iiswc_2020, author = {Jamet, Alexandre Valentin and Alvarez, Lluc and Jiménez, Daniel A. and Casas, Marc}, booktitle = {2020 IEEE International Symposium on Workload Characterization (IISWC)}, title = {Characterizing the impact of last-level cache replacement policies on big-data workloads}, year = {2020}, volume = {}, number = {}, pages = {134-144}, keywords = {Benchmark testing;Big Data;Stress;Social networking (online);Roads;Prediction algorithms;Kernel;cache management;big data;graph processing;workload evaluation;micro-architecture}, doi = {10.1109/IISWC50251.2020.00022}, issn = {}, month = oct, }